
苹果首次对外发布有关人工智能的论文 说了些什么?
2011 年苹果推出 Siri 的时候,似乎在人工智能上领先了其他大公司不少的距离——并非如此。在之后的 5 年里,Google、Facebook、亚马逊等大公司相继将人工智能提到了公司级核心战略的位置,苹果并未给人留下什么深刻的印象。
为了追赶竞争对手,在今年 9 月的秋季发布会上苹果正式推出了 iOS 10,着力宣传了其中不少通过人工智能的方法实现的功能,比如照片应用可以自动识别人脸来帮助用户管理照片等等。
在本月早些时候结束的 NIPS 大会上,苹果的人工智能总监,卡内基梅隆大学教授鲁斯·萨拉库蒂诺夫 (Russ salakhutdinov) 透露了苹果将要发布人工智能论文的消息。他的一张 PPT 截图吸引了人们的眼球:
苹果能发论文吗?能
我们能和学界积极交流吗?能

圣诞节前,一篇由多名苹果深度学习研究员署名的文章终于正式出现在了论文库 arXiv 的计算机视觉板块里。该论文标题为《Learning from Simulated and Unsupervised Images through Adversarial Training》(通过对抗网络使用模拟和非监督图像训练),描述了苹果正在使用的一种特殊的方法,能够显著降低训练图像识别用途神经网络的成本。
这篇论文提出的方法能够让神经网络使用计算机生成的“合成图片” (synthetic image) 训练,取得和使用真实世界照片 (real image) 训练一样好的效果。
具体来说,在人工智能学界和业界人们通常认为使用真实世界照片去训练图像识别系统的效果更好。但这样做的成本往往是很高的,因为计算机能看懂一张照片的前提是照片已经被打上了标记。
举个直观的例子:想让计算机看懂下图,需要提前把照片里的关键元素打上标记,这个是手那个是杯子等等。

但这种标记的工作很比较消耗时间、金钱和人力。当研究者在这些资源上比较稀缺的时候,也可以选择使用计算机声称并已经打好标记的合成图片。合成图片在业界看来劣势在于“不够真实”,导致使用合成图片训练的神经网络,在识别真实世界照片时性能并不算好。
在论文中,苹果宣称他们采用了一种类似于生成式对抗网络(Generative Adversarial Networks , GAN) 的神经网络模型。GAN 在过去比较主要的用途之一就是训练计算机生成拟真的照片,形象来讲,就是用一个生成“合成图片”的网络,和另一个提供真照片的数据集进行对抗,再用一个单独的鉴别网络进行鉴别。
苹果的科研人员在 GAN 基础之上,对模型做出了一些比较重大的调整,比如输入的不是随机向量而是合成照片,最终提出了这种他们称为“Simulated + Unsupervised”(模拟+未监督)的学习模型:
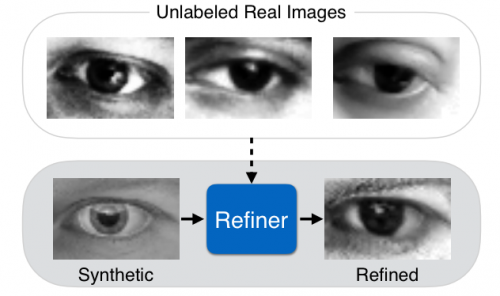
苹果认为,这篇论文的对计算机视觉做出的贡献,除了提出了新的学习模型之外,还包括使用了这个模型在完全无人工对图片标记的前提下成功训练出了一个优化网络 (Refiner),让计算机能够生成出更“真实”的合成照片——图片失真更少,真实性水准更稳定。
该论文的第一作者是 Ashish Shrivastava,苹果深度学习研究员。其他作者包括 Tomas Pfister、Oncel Tuzel、Wenda Wang、Russ Webb 和 Josh Susskind 。其中 Josh Susskind 是深度学习计算机视觉公司 Emotient 的创始人,该公司今年刚刚被苹果收购。



